Datenstrukturen 🗄️
⚠️ Wichtig: Dies ist ein Kapitel über verschiedene Arten von Datenstrukturen (nicht Datentypen!) und wie sie in Java implementiert sind bzw. werden können. Die Liste ist aber natürlich keineswegs vollständig! Es soll hier wirklich nur um jene Datenstrukturen gehen, die häufig im normalen, alltäglichen Gebrauch sind bzw. um “Klassiker”, die sich gut zum Lernen einer Programmiersprache selbst implementieren lassen. Ebenfalls enorm wichtige Datenstrukturen (wie etwa Heap oder Stack zur Speicherverwaltung) werden hier bewusst ausgespart, weil sie eher zu den IT-Grundlagen gehören, als in einen Java-Wegweiser.
Eine 👉 Datenstruktur ist ein Objekt, das Daten oder andere Objekte speichert bzw. referenziert. Es gibt zahlreiche Arten von Datenstrukturen, die sich jeweils in Aufbau und Funktionsweise (und somit in Vor- und Nachteilen) stark unterscheiden. Dieser Artikel thematisiert nur einige grundlegende Datenstrukturen, die sich sehr schön selbst in Java implementieren lassen.
💬 Für eine umfangreiche Übersicht über viele verschiedene Datenstrukturen sei 🔗auf diese Seite verwiesen!
Listen
Eine Liste ist ein abstraktes Konzept einer Datenstruktur, deren Elemente eine stabile Reihenfolge besitzen, mehrfach vorkommen können und keine durch die Definition der Liste beschränkte Anzahl haben.
Es sollen hier als Beispiel für selbst implementierte Listen-Strukturen die verketteten Listen vorgestellt werden - für die in der Java Class Library verfügbaren Implementationen von Listen, siehe Artikel zum 🔭 Collections Framework!
(Einfach) Verkettete Listen
💬 Es ist hier die Rede von einfach verketteten Listen. Im nächsten Abschnitt werden (darauf aufbauend) zweifach verkettete Listen besprochen.
Bei einer verketteten Liste handelt es sich um eine sehr einfache Datenstruktur, bei der die Daten sogenannten Knoten (engl.: nodes) zugeordnet sind. Diese Knoten bilden die eigentliche verkettete Liste (zusammen mit einem Start-Verweis auf den ersten Knoten!).
Ein einzelner Knoten besteht dabei aus nur zwei Elementen: Dem Datenfeld und einem Verweis (Referenz) auf den nächsten Knoten (Verkettung!):

Beispiel: Verkettete Liste mit Integer-Werten; Löschung eines Knotens
Somit “kennt” ein Knoten immer nur den von ihm aus nächsten Knoten in der Liste. Soll ein Knoten aus der Liste entfernt werden, muss nur die Referenz auf diesen Knoten (ausgehend vom Knoten davor) auf den nächsten Knoten abgeändert werden (siehe Grafik oben).
In Java sähe eine sehr einfache Implementation einer Verketteten Liste (mit Integer-Werten) etwa so aus:
public class Node {
public int value;
public Node next;
public Node (int value){
this.value = value;
}
}
💬 Auf private Klassenattribute sowie Getter und Setter wurde zugunsten der Übersichtlichkeit hier verzichtet. Eigentlich sollte natürlich beides vorhanden sein!
Aus Instanzen dieser simplen Klasse lässt sich bereits eine verkettete Liste konstruieren:
Node first = new Node(12); // Start-Knoten
first.next = new Node(99); // zweiter Knoten
first.next.next = new Node(37); // dritter Knoten
Auch das Entfernen des zweiten Knotens (wie in der Grafik oben) ist wie beschrieben möglich:
first.next = first.next.next;
Da nun keine Referenz auf den zweiten Knoten mehr existiert, ist dieser effektiv “entfernt” - d.h. das Objekt wird irgendwann vom Garbage Collector der JVM entsorgt.
Dieses effiziente Entfernen von Elementen ist einer der Vorteile von verketteten Listen. Ein weiterer ist die “von Natur aus” unbegrenzte Anzahl von Elementen, denn die Knoten-Objekte sind nicht linear im Speicher abgelegt, sondern können irgendwo verteilt gespeichert sein, solange sie einander referenzieren.
Allerdings werden im obigen Beispiel auch die Nachteile von verketteten Listen deutlich: Einzelne Elemente lassen sich nur über die Referenz vom Vorgänger-Knoten ansprechen. Soll also ein Knoten mit einem ganz bestimmten Wert (oder etwa der n-te Knoten der Liste) gefunden werden, muss linear über die Liste iteriert werden, bis der gesuchte Knoten gefunden ist. Eine sehr teuere Operation!
Zweifach verkettete Listen
Ausgehend von einfach verketteten Listen (siehe oben!) lassen sich zweifach verkettete Listen als eine konzeptuelle Erweiterung beschreiben, bei der jeder Knoten nicht nur den Folgeknoten, sondern auch den Vorgänger-Knoten referenziert. Somit kann (von jedem Knoten aus) die Liste in beide Richtungen durchlaufen werden:

Beispiel: Zweifach verkettete Liste mit Integer-Werten
Eine entsprechende Klasse sähe (wieder vereinfacht ohne private Klassenattribute!) etwa so aus:
public class Node {
public int value;
public Node previous;
public Node next;
// Konstruktor für Wert, etc. ...
}
Dadurch lassen sich bestimmte Operationen einfacher ausführen - etwa das Entfernen eines Knotens mit einem bestimmten Wert, denn der zu entfernende Knoten referenziert selbst die beiden Nachbarknoten, deren Referenzen (auf den zu löschenden Knoten) geändert werden müssen! Lesen Sie diesen Artikel, um mehr über die doppelt verknüpfte Liste zu erfahren.
Bäume
Ein Baum ist (u.a.) eine hierarchische Datenstruktur, die (ähnlich wie die verkettete Liste) Daten in Knoten speichert. Ein Knoten speichert außerdem Verweise auf die Knoten, die in der Baumstruktur direkt unter ihm liegen. Diese Verweise werden auch Kanten genannt. Ein Baum besitzt außerdem eine Wurzel (oder: Wurzelknoten), die ganz oben in der Hierarche steht.
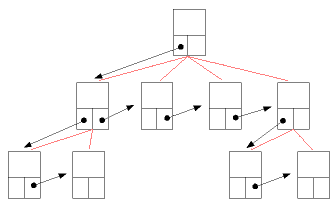
Quelle: commons.wikimedia.org; Matthias Kleine / CC BY-SA
{kind=link}
Es existieren viele Arten von spezialisierten Baumstrukturen - an dieser Stelle wollen wir aber nur auf die binären Suchbäume hinaus, da sich mit ihnen sehr gut weitere interessante Konzepte veranschaulichen und üben lassen (👉 Rekursion).
Binäre Suchbäume
Ein Binärbaum ist ganz einfach ein Baum, dessen Wurzel und Knoten maximal zwei Kind-Knoten (also zwei Referenzen auf darunterliegende Knoten / Nachkommen) besitzen.
Eine spezialform von Binärbäumen sind binäre Suchbäume. Diese werden bereits sortiert befüllt, d.h. es gibt eine Regel zum Einfügen von neuen Knoten, die jedem neu einzufügenden Knoten genau seinen Platz zuweisen. Nach dieser Regel ist die Baumstruktur anschließend sehr effizient durchsuchbar (👉 divide and conquer; Rekursion). Diese Regel besagt, dass der linke Nachkomme (linke Referenz auf Kind-Knoten) einen kleineren oder gleichen Wert enthalten muss und jeder rechte Nachkomme (rechte Referenz…) einen größeren oder gleichen Wert enthalten muss:
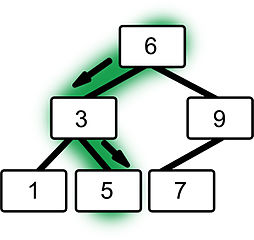
Quelle: commons.wikimedia.org; Mhombach / CC BY-SA
{kind=link}
Wenn ein Binärbaum nach dieser Regel aufgebaut ist, dann halndelt es sich um einen binären Suchbaum. Dieser Aufbau ermöglich nun eine sehr schnelle Suche nach einem bestimmten Knoten, da nach dem “divide and conquer“-Prinzip nur ein sehr kleiner Teil des Baumes durchsucht werden muss. In der Grafik oben ist etwa der Pfad zum Knoten (bzw. Blatt) mit dem Wert 5 hervorgehoben. Der Ablauf dieser Suche ist bei jedem Knoten mit dem Wert n (egal welchen Wert er trägt) gleich:
- Ist
nder gesuchte Wert?- Wenn ja: FERTIG!.
- Wenn nein: Weiter zu Schritt 2.
- Ist der gesuchte Wert größer als
n?- Wenn ja: Weiter zum linken Teilbaum mit Schritt 1.
- Wenn nein: Weiter zum rechten Teilbaum mit Schritt 1.
- Der gesuchte Wert ist nicht im Baum enthalten 😒
Dieser Vorgang eignet sich natürlich hervorragend für eine rekursive Implementierung!