Input / Output (I/O) ⏩
🚧 TODO: Alles…
Datenströme
eng.: streams
⚠ Dieser Abschnitt setzt voraus, dass du bereits weißt, was ein Datenstrom ist. Hier geht es dann um den Umgang mit Datenströmen in Java!
⚠ Hier geht es übrigens nicht um die Java Stream API, sondern um Input/Output-Streams, also Datenströme!
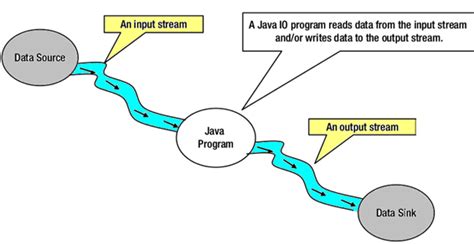 Quelle: java-latte.blogspot.com
Quelle: java-latte.blogspot.com
Die Java Standard-Library bietet zahlreiche Klassen für den Umgang mit Datenströmen. Diese lassen sich in zwei Gruppen aufteilen:
- Streams: Hierbei handelt es sich um sog. Byte Streams. Sie transportieren Daten in “Portionen” von aufeinander folgenden Bytes, also 8-Bit-Blöcken 🤓
- Readers / Writers: Dies sind sog. Character Streams. Sie sind speziell für textbasierte Daten gedacht, die Zeichen für Zeichen unter berücksichtigung lokaler Zeichensätze verarbeitet werden.
💬 Wir schauen uns hier die Klassen aus dem älteren Paket
java.ioan, weil diese (1.) ihren Dienst tun und (2.) alles bieten, was man für einfache Operationen mit Datenströmen und Puffern benötigt. Eine neuere (aber als Ergänzug gedachte) Schnittstelle zur Arbeit mit Dateien, Pfaden und Datenströmen bietet übrigens das Paket 🔗java.nio. Die Klasse 🔗Filesetwa besitzt einige statische Methoden wieFiles.write(...), die man sich ebenfalls ansehen sollte!
Byte Streams
Alle 🔗 Byte Stream-Klassen erweitern die (abstrakten) Klassen InputStream (Datenströme, die “von außen” kommen und von der Anwendung gelesen bzw. verarbeitet werden) oder OutputStream (Datenströme, in die von der Anwendung Daten geschrieben werden).
InputStream und OutputStream werden (weil sie abstrakte Klassen sind) nicht direkt instanziiert, sondern von unterschiedlichen auf bestimmte Daten-Quellen bzw. -Ziele spezialisierte Klassen erweitert. Zwei Beispiele sind …
-
FileInputStream/FileOutputStreamzum Lesen/Schreiben von Dateien -
ObjectInputStream/ObjectOutputStreamfür Objektserialisierung - …
Sehen wir uns zum Beispiel den Umgang mit einem FileOutputStream an, um einen String in eine Datei zu schreiben:
String s = "Ich hab 'ne Schlange im Stiefel!";
File f = new File("test.txt");
FileOutputStream fos = new FileOutputStream(f);
fos.write(s.getBytes());
fos.close();
⚠ Anmerkung: Der Code in diesem Beispiel wirft möglicherweise eine
FileNotFoundExceptionoder (allgemeiner) irgendeine andereIOException. Zugunsten der Übersichtlichkeit ist die Fehlerbehandlung in diesem Beispiel ignoriert worden - natürlich ist diese für solche Operationen aber notwendig!
Sehen wir uns die fünf Zeilen Code genauer an:
- Einen String erzeugen / einer Variable zuweisen
- Ein 🔗
File-Objekt erzeugen, welches die Datei test.txt (relativ zum Arbeitsverzeichnis) repräsentiert (diese Datei muss dafür nicht wirklich existieren!) - Einen
FileOutputStreamerzeugen und diesem dasFile-Objekt im Konstruktur übergeben (damit bezieht sich unserFileOutputStreamauf diese Datei!) - Den String
s(als Arraybyte[]) in den Datenstromfos, unserenFileOutputStream, schreiben - Den Datenstrom wieder schließen
Nun sollte auf der Festplatte im Arbeitsverzeichnis des gerade ausgeführten Programmes eine Datei test.txt mit dem Inhalt “Ich hab ‘ne Schlange im Stiefel!” liegen.
Analog zu diesem Beispiel funktionieren auch andere Byte Streams in Java!
Eigentlich werden Byte Streams eher dazu verwendet, um Daten an andere Programmteile weiterzureichen. Wenn es sich um textuelle Daten (wie in unserem Beispiel) handelt, die auch als Text im Programm verarbeitet wurden oder werden sollen, sollte man besser gleich die passendere Stream-Variante wählen, nämlich Character Streams (siehe unten)!
Character Streams
🔗 Character Streams transportieren textuelle Daten. Es lohnt sich, textuelle Daten mit speziellen Werkzeugen zu verarbeiten, denn die entsprechenden Klassen (etwa FileReader und FileWriter) tun dies in 🔗 Unicode-kompatibler Form (genauer in 🔗 UTF-16) und transformieren die Daten automatisch in den lokalen Zeichensatz.
Außerdem bieten FileReader und FileWriter etwas passendere Methoden für das an, was man hier tun will - sehen wir uns, angelehnt an das Beispiel von oben, das Schreiben in eine Datei mittels FileWriter an:
String s = "Ich hab 'ne Schlange im Stiefel!";
File f = new File("test.txt");
FileWriter writer = new FileWriter(f);
writer.write(s);
writer.close();
Man beachte, wie in der vierten Zeile die Methode write() direkt einen String annimmt! Die 👉 API unterscheidet sich darüber hinaus nicht zwangsläufig vom Beispiel oben. Aber wie gesagt: Der FileWriter schreibt diese Text-Daten unter Verwendung des im Betriebssystem festgelegten Zeichensatzes!
💬 Das wäre dann unter Windows (auf Deutsch) etwa CP 1252, unter Linux (und inzwischen auch unter Mac OS X) eher UTF-8.
Möchte man den verwendeten Zeichensatz ändern, übergibt man dem FileWriter (bzw. FileReader - je nach dem) diese Information einfach im Konstruktor. Die Java-Klasse StandardCharsets bietet komfortablen, statischen Zugang zu den üblichsten Charsets:
new FileWriter(file, StandardCharsets.UTF_8);
Buffering
deu.: Pufferung
Ohne eine 🔗 Pufferung wird jeder Schreibvorgang eines Datenstroms einzeln abgearbeitet. Dadurch werden viele unnötige Ressourcen (Dateizugriffe, Netzwerkanfragen, etc.) mobilisiert, wodurch wiederum der jeweilige Vorgang stark verlangsamt werden kann.
Um dies zu verhindern verwendet man besonders für Datenströme, die größere Datenmengen transportieren* und dabei nicht etwa ohnehin regelmäßig auf das nächste Datenpaket warten*, einen Puffer, der größere Mengen von Datenblöcken zwischenspeichert, die dann am Stück verarbeitet werden können. Dadurch können Vorgänge, an denen Datenströme beteiligt sind, enorm beschleunigt werden.
* Also etwa: “der gesamte Text der Bibel wird von der Festplatte gelesen” und nicht “ein User gibt Zeile für Zeile Befehle auf der Kommandozeile ein” (dafür wäre keine Pufferung notwendig)
Die Puffer-Klassen für Datenströme in Java heißen …
-
BufferedInputStreambzw.BufferedOutputStreamfür Binary Streams (siehe oben) und -
BufferedReaderbzw.BufferedWriterfür Character Streams (siehe ebenfalls oben)
Die 👉 API für diese Puffer-Klassen ist so gestaltet, dass einfach der passende Puffer als 👉 Wrapper für den genutzten Datenstrom verwendet wird. Dazu wird das Datenstrom-Objekt dem Puffer-Objekt im Konstruktor übergeben. Von da an nutzt man nur noch das Puffer-Objekt für den Zugriff auf den Datenstrom, denn dieses Verwaltet den “verpackten” Datenstrom.
In Anlehnung an das Beispiel von oben puffern wir doch einfach mal das Schreiben von Text in eine Datei:
String s = "Ich hab 'ne Schlange im Stiefel!";
File f = new File("test.txt");
FileWriter writer = new FileWriter(f);
BufferedWriter bw = new BufferedWriter(writer); // Puffer!
bw.write(s); // in den Puffer schreiben
bw.close(); // Puffer schließen (schließt auch Datenstrom!)
💬 Natürlich müsste man für dieses Minimalbeispiel nicht wirklich einen Puffer verwenden!
Die anderen Puffer-Klassen funktionieren nach dem selben Prinzip.
🔗 Weitere Informationen und Beispiele zum Puffern von Datenströmen in Java finden sich z.B hier oder hier.
Objekt-Serialisierung
Mit Objekt-Serialisierung ist das Überführen von Objekten und deren Zustand in eine sequenzielle Datenstruktur (Datenstrom!) gemeint - meist zum Zweck der Speicherung von Objektzuständen in einer Datenbank oder als Datei.
👩🏫 Die Deserialisierung beschreibt dementsprechend den umgekehrten Prozess!
ObjectInputStream und ObjectOutputStream
Java hält für die Objekt-Serialisierung die beiden genau darauf spezialisierten Klassen ObjectInputStream und ObjectOutputStream bereit. Sie lesen bzw. schreiben einen Datenstrom, der Objekte und ihre Zustände in sequentieller Form (Byte für Byte) transportiert.
Ob dieser Datenstrom dann in eine Datei oder ein anderes Ziel “gelenkt” wird, hängt wieder davon ab, welchen weiteren Datenstrom wir “anschließen” (z.B: einen FileOutputStream zum Schreiben in eine Datei).
Wichtig: Es lassen sich generell nur Objekte serialisieren, deren zugrundeliegende Klasse das Interface Serializable implementiert (siehe nächster Abschnitt).
Das Interface Serializable
Es handelt sich bei Serializable um ein reines Markierungs-Interface (oder eng.: marker interface). Das bedeutet, dass es keine (!) Methoden definiert, die von einer Klasse implementiert werden müssten, sondern lediglich eine Art Versicherung der programmierenden Person darstellt, dass Instanzen dieser Klasse “serialisierbar” sein sollen.
Es gibt hinsichtlich der “Serialisierbarkeit” einer Klasse keine technischen Einschränkungen. Ob eine Klasse das Interface Serializable implementieren kann (oder sollte), hängt einzig davon ab, ob dies Sinn ergibt: Eine Klasse User, die Daten zu einem User speichert, könnte durchaus serialisierbar sein. Hingegen sollte man Instanzen einer Klasse File oder Connection, deren Zustand aus Daten zu einem Plattform- bzw. Zeit-abhängigen Sachverhalt besteht, nicht als Serializable markieren. Und zwar einfach, weil es nicht sinnvoll wäre.
⚠ Alle Unterklassen einer Klasse, die
Serializableimplementert, sind automatisch ebenfalls alsSerializablemarkiert (logisch, denn sie erben ja diese Eigenschaft!). Allerdings sind Klassen, die als Typ von Instanzvariablen oder als Typ von Elementen einer Datenstruktur dienen nicht automatisch auchSerializable. In diesem Fall mussSerializablein diesen betreffenden Klassen ebenfalls “implementiert” sein!
Beispiel
Nehmen wir einmal eine Klasse User an:
import java.io.Serializable;
public class User implements Serializable {
private static final long serialVersionUID = 4057375706308532141L;
private String userName;
private String mail;
public User(String userName, String mail) {
super();
this.userName = userName;
this.mail = mail;
}
// ... Getter, Setter, ...
}
💬 Die Konstante
serialVersionUIDist eine Zahlenfolge, die die Version dieser Klasse repräsentiert. Denn ein Objekt vom TypUser, das aus einer älteren Version der KlasseUsererstellt und dann serialisiert wurde, kann u.U. nicht unter Verwendung einer neueren Version vonUserwieder deserialisiert werden (siehe unten!)! Die Eclipse IDE erzeugt bei Bedarf z.B. unter Einbeziehung des Klassennamens, der Attribute usw. automatisch so eineserialVersionUID.
Diese Klasse implementiert Serializable (ohne dafür Methoden implementieren zu müssen) und ist somit als “serialisierbar” markiert.
Nun können wir ein Objekt vom Typ User mit all den Daten, die seinen Zustand ausmachen, in eine Datei speichern:
// User-Objekt erzeugen
User u = new User("MaxiMustermann", "mmust@lycos.com");
// der Name der Datei ist frei gewählt
File f = new File("user.obj");
// Stream zum Schreiben der Datei
FileOutputStream fos = new FileOutputStream(f);
// Stream zum Serialisieren des Objektes
ObjectOutputStream oos = new ObjectOutputStream(fos);
// User-Objekt serialisieren und in Datei schreiben
oos.writeObject(u);
// Stream am Ende schließen!
oos.close();
⚠ Auch hier wurde (wie in den Beispielen oben) zugunsten der Übersichtlichkeit auf die richtige (und nötige!) Fehlerbehandlung verzichtet.
Mit einer hübschen Fehlerbehandlung (unter Verwendung von try-with-resources) könnte dieser Code so aussehen:
User u = new User("MaxiMustermann", "mmust@lycos.com");
try(ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream(new File("user.obj")))){
oos.writeObject(u); // Objekt serialisieren + schreiben
oos.close(); // Streams schließen
} catch (FileNotFoundException e) {
e.printStackTrace(); // ...
} catch (IOException e) {
e.printStackTrace(); // ...
}
Um das Objekt, das wir nun in eine Datei gespeichert haben, wieder zu lesen und zu deserialisieren, kehren wir diesen Prozess einfach um. Wir verwenden dazu satt der OutputStreams einfach InputStreams.
User u;
File f = new File("user.obj");
FileInputStream fis = new FileInputStream(f);
ObjectInputStream ois = new ObjectInputStream(fis);
u = (User) ois.readObject(); // Casting zu User!!!
ois.close();
System.out.println(u.getUserName());
⚠ …wieder ohne Fehlerbehandlung!
Dieser Code würde tatsächlich MaxiMustermann auf der Konsole ausgeben - der Zustand des Objektes ist wiederhergestellt!
Wichtig: Es ist eine Typumwandlung (casting) zum entsprechenden Datentyp nötig, denn die Objektserialisierung weiß lediglich, dass es ist um ein Object handeln muss - alles Weitere liegt in unserer Verantwortung!
🔗 Als weitere Lektüre eignet sich u.a. dieser Artikel!
Scanner
Die Klasse Scanner (Paketpfad java.util.Scanner) bietet eine sehr komfortable Schnittstelle zum “scannen” von Textdaten. Einem Scanner kann eine Vielzahl von Datenquellen im Konstruktor übergeben werden, die dann Stück für Stück geparst werden.
Wonach der Text aufgetrennt wird, also an welchem Trennzeichen (Delimiter), lässt sich beliebig festlegen. Nehmen wir als Beispiel den folgenden Text, der in einer Datei nicht-rilke.txt im Arbeitsverzeichnis unseres Programmes gespeichert ist:
Ein Raabe geht im Feld spazieren. Da fällt der Weizen um!
Wir können dann eine Referenz auf diese Datei als File-Objekt an einen Scanner übergeben …
File f = new File("nicht-rilke.txt");
Scanner s = new Scanner(f);
… und festlegen, an welchen Stellen der Text zerlegt werden soll …
s.useDelimiter(" ");
… die Methode useDelimiter() nimmt einen Regulären Ausdruck entgegen - hier verwenden wir einfach einen “literal” Whitespace, also ein Leerzeichen.
Und nun lesen wir unseren Text Stück für Stück:
while(s.hasNext()) {
System.out.println(s.next());
}
Der Ergebnis:
Ein
Raabe
geht
im
Feld
spazieren.
Da
fällt
der
Weizen
um!
Mit dem Delimiter a würden wir (unsinnigerweise) nach den kleinen Buchstaben “a” als Trennzeichen festlegen:
Ein R
be geht im Feld sp
zieren. D
fällt der Weizen um!
User-Input über Stdin mit Scanner
Die Klasse Scanner kann außerdem dazu genutzt werden, um auf einfache Weise User-Input über 👉 Stdin (Standard Input) zu erhalten. Dazu wird das Java-Objekt, das diesen Datenstrom repräsentiert (System.in) als Parameter an den Konstruktor der Scanner-Klasse übergeben. Diese bietet eine sehr komfortable Schnittstelle für solche textbasierten Datenströme:
Scanner in = new Scanner(System.in);
String input = in.nextLine();
System.out.println("User hat eingegeben: " + input);
in.close();
In einem größeren Zusammenhang könnte das etwa so aussehen:
import java.util.Scanner;
class ReadingStdin {
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
String input = null;
do {
// noch kein Input vorhanden?
if (input != null){
// wurde "exit" oder "EXIT" eingegeben?
if (input.equalsIgnoreCase("exit")){
System.exit(0);
}
// reagieren
System.out.println("You just typed: \"" + input + "\"\n");
}
// Aufforderung zur Eingabe
System.out.print("Type something here: ");
} while ((input = in.nextLine()) != null);
// Scanner muss wieder geschlossen werden!
in.close();
}
}
Das Ergebnis sieht dann so aus:
Type something here: Hello
You just typed: "Hello"
Type something here: World
You just typed: "World"
Type something here: █
🔗 Weitere gute Quellen zum Thema I/O (Input/Output) in Java findest du (im Allgemeinen) hier und (im Speziellen) hier.